INDUSTRY
Communications, Media and Information Services

Connect. Curate. Comprehend: Unlocking Value Beyond Boundaries
Highlights
- Credit bureaus and rating agencies depend heavily on externally sourced consumer financial transactions and market data, which is often riddled with quality issues.
- AI and generative AI (GenAI) can analyze large data sets, identifying potential unknown anomalies upstream, leading to an elevated customer experience.
- GenAI can enable a framework allowing IS companies to implement a data quality engine, reducing costs and increasing efficiency.
In this article
Unequal bytes
Information services (IS) enterprises depend on rule-based or supervised learning models, which are limited in their efficacy in detecting irregularities.
Credit bureaus, rating agencies, and information services providers rely heavily on externally sourced financial transactions and market data. They've established an error-detection process using proprietary models that generate judgment on creditworthiness, while providing other analytics. This evaluation has a far-reaching impact while assessing an individual's or a company's financial stability and ability to secure credit. Rule-based anomaly detection for externally sourced data is standard practice, though not scalable, or capable of detecting new or unknown scenarios for current and new channels.
GenAI will allow irregularity detection in the source data during ingestion, reducing manual interventions and minimizing costs in the long run. Lenders would have access to accurate data, allowing them to extend the desired credit to consumers and companies.
Sifting through data
For information services providers, data anomalies can prove expensive.
Anomalies in data can vary, and the cause could be related to source system errors or human irregularity. Basing credit decisions on erroneous data can lead to considerable loss for the individual or the organization with far-reaching social and economic impact. Fraudulent activity in such cases can cause irreparable damage to enterprises.
Errors in credit reports can be attributed to not being able to detect unknown scenarios properly. The direct impact of poor credit scores on consumers can range from higher insurance premiums to higher interest rates on credit, or even denial of credit.
Currently, most IS enterprises follow a rule-based system for anomaly detection, which involves continual monitoring of incoming data. This system has hundreds or even thousands of rules, which are updated whenever a new scenario occurs as the data moves into downstream systems. The updates to these rules and their execution to detect errors are iterative, requiring manual intervention and supervision. Credit rating providers need to invest in safeguarding processes against poor-quality data through iterative manual interventions and continuous rule updates. In most situations, the technologies in use are outdated and resistant to detection of new anomaly patterns.
With AI-ML, some of these processes have become more streamlined, with AI techniques being leveraged to improve data anomaly detection. Enterprises must continuously invest in technology programs to improve data quality while deploying an adequate workforce to oversee and intervene when needed. With GenAI, anomaly detection can become significantly advanced with high efficiency gains.
Pioneering change
Rule-based anomaly detection requires knowledge of all possible unusual scenarios, while GenAI can detect new irregularities in a dataset.
Often, with source datasets, there are two challenges:
- Erroneous data elements are inseparable from correct data.
- Anomalies are intrinsically embedded in the datasets, which are otherwise unknown or yet to be discovered.
Unlike rule-based systems and traditional AI approaches, GenAI learns, adapts, and applies knowledge from datasets to infer scenarios, simulating a near-human interpretation. GenAI-enabled anomaly detection can:
Automate simulation: This can be done using the typical data ingestion pipeline of a credit rating provider. The approach used is a pioneering methodology for the ‘unknown unknowns’ situation, wherein transaction data is processed through a GenAI-based model to determine its quality.
For the simulation, an automated batch process was developed to analyze the incoming data, and the solution was designed to continuously detect inconsistent data patterns, through semi-supervised machine learning on an ongoing basis.
A trading information dataset was prepared as input data and used for training and testing anomaly detection. Some of the key fields used in the data set included:
- Company scrip code
- Date of listing of the company scrip
- Date of trade
- Volume of traded transaction
- Unit price of the scrip
- Date of delinquency
- Date of founding
- Account status
For execution and detecting the anomalies, a thousand records were generated with one or more of the following anomalies:
- Trading date is later than date of delinquency
- Volume of traded transaction is greater than zero for inactive accounts
- Date of listing is earlier than date of founding
About 100,000 clean data records were created for training and testing the model prior to the execution with anomalistic data. A two-stage approach was adopted to identify bad data and attribute reasons for the anomaly within the data set, using:
- Data segregation between good and bad clusters: This was achieved through unsupervised and semi-supervised machine learning (ML) for segregation between good and bad data (See figure 1). Autoencoder neural network can be leveraged to identify anomalies by identifying reconstruction error threshold that can delineate good from bad data.
- Attribution for records in bad cluster: Supervised ML was deployed to classify errors from bad data cluster identified in the first stage. Multi-class classification algorithms were used to perform the task based on labelled training data, which can be on a neural network or based on ML models.
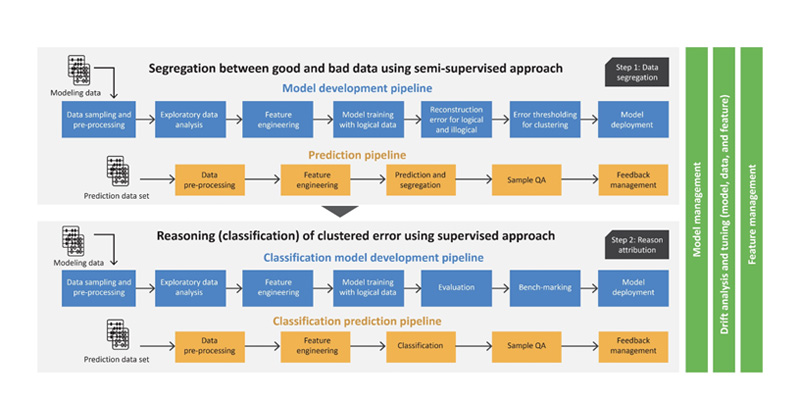
Figure 1 : A chart of bad data segregation steps
Figure 1 : A chart of bad data segregation steps
Feature engineering was leveraged for the date fields, and different hyperparameters were tuned over a hundred iterations to conduct this simulation using Google Colab with Google Vertex AI. The technology stack included TensorFlow, Pandas, NumPy, Matplotlib, Sklearn, and Openpyxl. The simulation model was tested using a new set of bad and good data which resulting in:
- Identification of mean squared error (MSE) indicating how the captured MSE for bad data is different from good data.
- Reason attribution as a multi-class classification using supervised learning.
- F measure as the key metric for measurement.
- Understanding how the model could not reconstruct bad data patterns, and successfully exhibited the capability to separate clean data from bad data.
Moving ahead with GenAI
Integration of GenAI in anomaly detection for credit decisioning can optimize costs, mitigate risks, and improve accuracy.
GenAI can automatically detect and filter out unknown errors using supervised learning models, improving the efficacy of data quality frameworks. This technique and approach can be applied to a variety of different other use cases across different industry domains which require data analysis, like network fault detection or fraud detection, leading to enhanced report accuracy and speed. Automated detection algorithms can also be applied before rule-based data quality checks.
Enterprises using this approach will be able to replace expensive data quality tools with a manageable and automated data quality check engine, that requires easy maintenance. By integrating GenAI-powered data quality pipeline for anomaly detection, credit rating providers can enable a fundamentally clean data backbone for their products and services.




